

统计模型驱动的查询处理技术
发布时间:2012/4/8 15:33:52 访问次数:1459
加州大学的Deshpande等提出了一种模型驱动 ISO124P的查询处理方法[17],该方法的思想是:首先基于已经存储和正在产生的感知数据,建立一个感知数据的统计数学模型,然后基于这个模型来回答用户的查询。这种数据模型是对过去感知数据分布情况的总结(如是某种属性的高斯分布),利用统计模型不仅可以计算出属性的变化趋势,还可以给出属性最可能取值的置信区间和置信度,当置信度达到一定要求(可以是用户定义的,也可以是系统给定的门限标准)时可以仅利用模型就给出比较可信的属性值;当未达要求时根据模型也可计算出需要获取哪些位置的哪些属性值,而不必盲目查询网络中的各种感知数值。
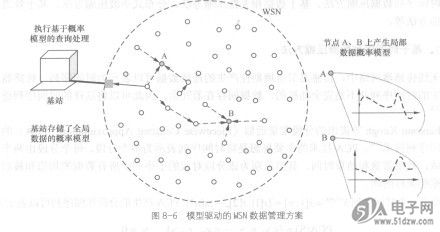
由于统计模型的参数表示和基于统计模型的查询计算较为复杂,因此除了在基站端计算网络全局数据的统计模型外,网内普通传感器节点上由于存储和计算能力限制不存储模型或者仅存储本节点(或包括相邻一跳节点)的一个或几个感知属性的统计模型。例如,在图8-6所示的基于概率的存储模型中,基站计算机上存储网内所有属性的概率模型,而在网内节点A和B处存储本节点附近的(一跳范围内的)同类型属性的概率统计模型,A节点存储附近的光强属性值统计分布模型,B节点存储附近温度属性值分布模型。利用节点A和B上的局部数据概率模型可以判断并剔除错误数据,找出有问题的邻居节点。
基于模型驱动的查询处理方法的优点如下。
①利用模型可以计算出还需要哪些位置的哪些数据,减少查询的盲目性,降低网内查询处理的数据量。
②利用统计模型可以计算数据之间的相关性信息,利用数据之间的相关性可以用查询节能属性数据的方式代替查询耗能多的属性,从而实现查询节能。
③根据概率模型可以辨别出不可靠的数据及失效的节点,可提供给用户网络中存在问题的节点信息。
④提供用户查询结果的同时给出关于查询结果的精确度,这对于科学工作者来说是很有用处的。
⑤根据模型预测分析未来数据的变化趋势,有利于实现发展趋势预测。
然而,这种方案也存在一些不足,具体如下。
①要处理不断连续变化的实时数据流,需要有良好的算法以实时更新数据的概率模型。
②传感器节点端存储概率模型和进行复杂的概率分布计算,需要耗费一定的存储资源和计算时间。
加州大学的Deshpande等提出了一种模型驱动 ISO124P的查询处理方法[17],该方法的思想是:首先基于已经存储和正在产生的感知数据,建立一个感知数据的统计数学模型,然后基于这个模型来回答用户的查询。这种数据模型是对过去感知数据分布情况的总结(如是某种属性的高斯分布),利用统计模型不仅可以计算出属性的变化趋势,还可以给出属性最可能取值的置信区间和置信度,当置信度达到一定要求(可以是用户定义的,也可以是系统给定的门限标准)时可以仅利用模型就给出比较可信的属性值;当未达要求时根据模型也可计算出需要获取哪些位置的哪些属性值,而不必盲目查询网络中的各种感知数值。
由于统计模型的参数表示和基于统计模型的查询计算较为复杂,因此除了在基站端计算网络全局数据的统计模型外,网内普通传感器节点上由于存储和计算能力限制不存储模型或者仅存储本节点(或包括相邻一跳节点)的一个或几个感知属性的统计模型。例如,在图8-6所示的基于概率的存储模型中,基站计算机上存储网内所有属性的概率模型,而在网内节点A和B处存储本节点附近的(一跳范围内的)同类型属性的概率统计模型,A节点存储附近的光强属性值统计分布模型,B节点存储附近温度属性值分布模型。利用节点A和B上的局部数据概率模型可以判断并剔除错误数据,找出有问题的邻居节点。
基于模型驱动的查询处理方法的优点如下。
①利用模型可以计算出还需要哪些位置的哪些数据,减少查询的盲目性,降低网内查询处理的数据量。
②利用统计模型可以计算数据之间的相关性信息,利用数据之间的相关性可以用查询节能属性数据的方式代替查询耗能多的属性,从而实现查询节能。
③根据概率模型可以辨别出不可靠的数据及失效的节点,可提供给用户网络中存在问题的节点信息。
④提供用户查询结果的同时给出关于查询结果的精确度,这对于科学工作者来说是很有用处的。
⑤根据模型预测分析未来数据的变化趋势,有利于实现发展趋势预测。
然而,这种方案也存在一些不足,具体如下。
①要处理不断连续变化的实时数据流,需要有良好的算法以实时更新数据的概率模型。
②传感器节点端存储概率模型和进行复杂的概率分布计算,需要耗费一定的存储资源和计算时间。
 相关技术资料
相关技术资料- 4-5黑白电视机整机方框图
- 2-3反向峰值电压
- 4-8统计模型驱动的查询处理技术
热门点击
- USB接口设计
- 音频编解码模块
- IEEE 802.15.4标准
- 电容器的基本特性
- WX1、WX2和WX3型线绕电位器
- 无线通信芯片CC2420
- 磁性天线
- 基于无线传感器网络的多网络融合系统结构
- 中央处理模块
- MEMS技术基本原理
推荐技术资料
- 自制智能型ICL7135
- 表头使ff11CL7135作为ADC,ICL7135是... [详细]
 公网安备44030402000607
公网安备44030402000607





