
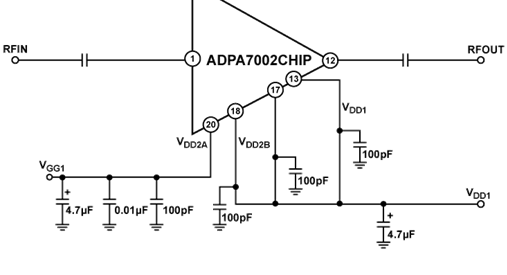
FPGA打造了EdgeBoard嵌入式AI解决方案
发布时间:2020/5/21 22:44:22 访问次数:1695
XRC240算力体现着人工智能(AI)技术具体实现的能力,实现载体主要有CPU、GPU、FPGA和ASIC四类器件。CPU基于冯诺依曼架构,虽然灵活,却延迟很大,在推理和训练过程中主要完成其擅长的控制和调度类任务。GPU以牺牲灵活性为代价来提高计算吞吐量,但其成本高、功耗大,尤其对于推理环节,并行度的优势并不能完全发挥。专用ASIC芯片开发周期长,资金投入大,由于其结构固化无法适应目前快速演进的AI算法。FPGA因其高性能、低功耗、低延迟、灵活可重配的特性,被广泛地用作AI加速,开发者无需更换芯片,即可实现优化最新的AI算法,为产品赢得宝贵的时间。
由此,百度基于FPGA打造了EdgeBoard嵌入式AI解决方案,能够提供强大的算力,支持定制化模型,适配各种不同的场景,并大幅提高设备端的AI推理能力,具有高性能、高通用、易集成等特点。本文将主要介绍EdgeBoard中神经网络算子在FPGA中的实现。

一类是指数运算,另一类是乘加运算。前者主要位于激活函数层,后者是深度学习涉及最多也是最基础的运算。乘加运算根据kernel的维度不同,又可分为向量型和矩阵型,在EdgeBoard中划分为三个运算单元,分别为向量运算单元(VPU: vector processing unit)、矩阵运算单元(MPU: matrix processing unit)和指数激活运算单元(EXP-ACT: exponential activation unit)。
向量运算单元VPU负责实现dw-conv(depth-wise convolution),完成3维输入图像(H x W x C)和3维卷积核(K1 x K2 x C)的乘加操作。其中一个卷积核负责输入图像的一个通道,卷积核的数量与上一层的通道数相同,该过程如图6所示。图7表示的是一个通道内以kernel 2x2和stride 2为例的计算过程。

EdgeBoard通过复用VPU一套计算资源实现了average/max pooling,elementwise add/sub,scale,batch-normalize,elementwise-mul和dropout等多种算子。
Average pooling可以看作是卷积核参数固定的dw-conv,即将求和后取平均(除以卷积核面积)的操作转换成先乘以一个系数(1/卷积核面积)再求和。如图8所示,该例子中卷积核大小为2x2,卷积核参数即为1/4。卷积核固定的参数可以类似于dw-conv下发卷积核的方式由SDK封装后下发,也可以通过SDK配置一个参数完成,然后在FPGA中计算转换,这样节省卷积核参数传输的时间。另外,max-pooling算子与average pooling的计算过程类似,只需要将求均值操作换成求最大值的操作,其余挖窗、存取数等过程保持不变。
Elementwise add/sub完成两幅图像对应元素的相加或相减,不同于dw-conv的是它有两幅输入图像。如果我们控制两幅图像的输入顺序,将两幅图像按行交错拼成一幅图像,然后取卷积核为2x1,行stride为1,列stride为2,pad均设置成0,则按照dw-conv的计算方式就完成了elementwise的计算。通过在FPGA中设置当前像素对应的kernel值为1或-1,就可以分别实现对应elementwise add和elementwise sub两个算子。
深圳市唯有度科技有限公司http://wydkj.51dzw.com/
(素材来源:ttic和eechina.如涉版权请联系删除。特别感谢)
XRC240算力体现着人工智能(AI)技术具体实现的能力,实现载体主要有CPU、GPU、FPGA和ASIC四类器件。CPU基于冯诺依曼架构,虽然灵活,却延迟很大,在推理和训练过程中主要完成其擅长的控制和调度类任务。GPU以牺牲灵活性为代价来提高计算吞吐量,但其成本高、功耗大,尤其对于推理环节,并行度的优势并不能完全发挥。专用ASIC芯片开发周期长,资金投入大,由于其结构固化无法适应目前快速演进的AI算法。FPGA因其高性能、低功耗、低延迟、灵活可重配的特性,被广泛地用作AI加速,开发者无需更换芯片,即可实现优化最新的AI算法,为产品赢得宝贵的时间。
由此,百度基于FPGA打造了EdgeBoard嵌入式AI解决方案,能够提供强大的算力,支持定制化模型,适配各种不同的场景,并大幅提高设备端的AI推理能力,具有高性能、高通用、易集成等特点。本文将主要介绍EdgeBoard中神经网络算子在FPGA中的实现。
一类是指数运算,另一类是乘加运算。前者主要位于激活函数层,后者是深度学习涉及最多也是最基础的运算。乘加运算根据kernel的维度不同,又可分为向量型和矩阵型,在EdgeBoard中划分为三个运算单元,分别为向量运算单元(VPU: vector processing unit)、矩阵运算单元(MPU: matrix processing unit)和指数激活运算单元(EXP-ACT: exponential activation unit)。
向量运算单元VPU负责实现dw-conv(depth-wise convolution),完成3维输入图像(H x W x C)和3维卷积核(K1 x K2 x C)的乘加操作。其中一个卷积核负责输入图像的一个通道,卷积核的数量与上一层的通道数相同,该过程如图6所示。图7表示的是一个通道内以kernel 2x2和stride 2为例的计算过程。
EdgeBoard通过复用VPU一套计算资源实现了average/max pooling,elementwise add/sub,scale,batch-normalize,elementwise-mul和dropout等多种算子。
Average pooling可以看作是卷积核参数固定的dw-conv,即将求和后取平均(除以卷积核面积)的操作转换成先乘以一个系数(1/卷积核面积)再求和。如图8所示,该例子中卷积核大小为2x2,卷积核参数即为1/4。卷积核固定的参数可以类似于dw-conv下发卷积核的方式由SDK封装后下发,也可以通过SDK配置一个参数完成,然后在FPGA中计算转换,这样节省卷积核参数传输的时间。另外,max-pooling算子与average pooling的计算过程类似,只需要将求均值操作换成求最大值的操作,其余挖窗、存取数等过程保持不变。
Elementwise add/sub完成两幅图像对应元素的相加或相减,不同于dw-conv的是它有两幅输入图像。如果我们控制两幅图像的输入顺序,将两幅图像按行交错拼成一幅图像,然后取卷积核为2x1,行stride为1,列stride为2,pad均设置成0,则按照dw-conv的计算方式就完成了elementwise的计算。通过在FPGA中设置当前像素对应的kernel值为1或-1,就可以分别实现对应elementwise add和elementwise sub两个算子。
深圳市唯有度科技有限公司http://wydkj.51dzw.com/
(素材来源:ttic和eechina.如涉版权请联系删除。特别感谢)
 相关技术资料
相关技术资料- 7-15高分子混合铝电解电容器应用探究
- 7-15高效节能4kW双向PFC电源方案解读
- 7-15离散半导体元件(晶体管、二极管等)技术参数设计
- 7-15CommonGround Human AI核心技术简
- 7-15520线车规级数字化激光雷达应用前景
- 7-15MPronto-12 (M12 Push Pull 连接器R
- 7-14NeuPro NPUs+ SensPro DSP技术参数设计
- 7-14双通道ATA-2022H高压放大器
- 7-14旗舰大模型Grok 4、Grok 4 API发展趋势
- 7-14耦合仿真技术及高保真模型试验技术应用探究
- 7-14GPU、FPGA、ASIC。GPU、FPGA技术解释
- 7-14ASIC/FPGA/GPU芯片及边缘-云端
 公网安备44030402000607
公网安备44030402000607





