
redis是一个开源的使用C语言编写的一个kv存储系统
发布时间:2019/9/2 14:55:06 访问次数:2861
关于Redis
redis是一个开源的使用C语言编写的一个kv存储系统,是一个速度非常快的非关系远程内存数据库。它支持包括String、List、Set、Zset、hash五种数据结构。除此之外,通过复制、持久化和客户端分片等特性,用户可以很方便地将redis扩展成一个能够包含数百GB数据和每秒处理上百万次的请求的系统。目前支持多种语言的api,方便用户使用。
redis同时也内置了事务、LUA脚本、复制等功能,提供两种持久化选项,一种是每隔一段时间将数据导入到磁盘(快照模式),另一种是追加命令到日志中(AOF模式)。如果只是作为高效的内存数据库使用也可以关闭持久化功能。通过哨兵(sentinel)和自动分区(Cuuster)的方式可以提高redis服务器的高可用性。
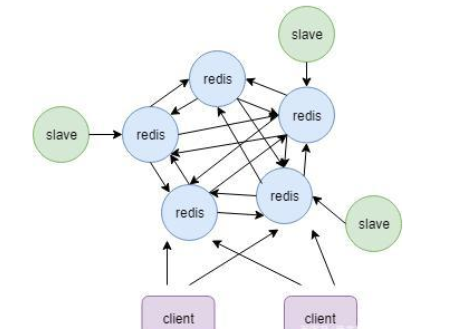
与关系型数据库相比,redis的命令请求不需要经过查询分析器或查询优化器进行处理,也避免了更新数据时引起的随机读\写,这些慢操作。它直接读写内存中的数据,并且数据是按照一定的数据结构存储的。所以它的速度非常快。
不同于memcached等完全基于内存的缓存中间件,Redis同时还提供了持久化功能,这也是为什么Redis不仅可以用来做数据缓存还可以用来做数据存储,服务器节点宕机之后可以通过事先持久化的数据还原数据到某个时间点的状态。Redis提供了两种持久化机制RDB和AOF,准确的讲应该是三种,Redis还提供了虚拟内存机制,但是性能比较差,使用场景有限。
RDB持久化是把当前数据库中的数据备份到一个RDB文件中,RDB文件是一个经过压缩的二进制文件,通过这个文件可以还原生成RDB文件时的数据库状态。
Redis提供了两个命令用于生成RDB文件,即SAVE和BGSAVE。SAVE命令会阻塞主进程,在执行该命令的过程中服务器会拒绝客户端命令。只有当SAVE命令执行完之后服务器才会继续处理客户端的命令,而BGSAVE命令是在子进程中执行,在执行该命令的过程中服务器还可以继续处理客户端的命令。SAVE命令和BGSAVE命令不能同时执行,当正在执行BGSAVE命令时,客户端发送的SAVE命令会被拒绝,两个BGSAVE命令也不能同时执行。
服务器在900秒之内对数据库进行了至少一次修改。服务器在300秒之内对数据库进行了至少10次修改。服务器在60秒之内对数据库进行了至少10000次修改。Redis通过一个saveparam结构体来保存save参数:
intset优化set
当set集合中的元素为整数且元素个数小于配置set-max-intset-entries值时,使用intset数据结构存储,否则转化为Dict结构,Dict实际是Hash Table的一种实现,key为元素值,value为NULL,这样即可在O(1)时间内判断集合中是否包含某个元素。

intset中有三种类型数组:int16_t类型、int32_t 类型、 int64_t 类型。至于怎么选择是那种类型的数组,是根据其保存的值的取值范围来决定的,初始化时是 int16_t,根据 set 中的***值在[INT16_MIN, INT16_MAX] , [INT32_MIN, INT32_MAX], [INT64_MIN, INT64_MAX]的那个取值范围来动态确定整个数组的类型。例如set一开始是 int16_t 类型,当一个取值范围在 [INT32_MIN, INT32_MAX]的值加入到 set 时,则将保存 set 的数组升级成 int32_t 的数组。
服务器结构体redisServer添加了三个字段:saveparams字段,保存所有的save参数。dirty字段,来保存上一次成功执行SAVE或BGSAVE命令之后,服务器对数据库执行的修改次数。lastsave字段,记录服务器上一次执行SAVE和BGSAVE的UNIX时间戳。RDB是通过备份某个时间点的数据来保存数据库状态,而AOF是通过保存服务器所执行的命令来保存数据库的状态的。当结点宕机重启时通过载入AOF文件并且执行文件中的命令就可以恢复生成AOF文件时的数据库状态,如果同时存在RDB文件和AOF文件,服务器优先载入AOF文件来还原数据库状态。
AOF实现分为三步:命令追加、文件写入、文件同步。现代操作系统中为了提高文件写入效率,当用户调用了write函数时操作系统通常会将写入的数据暂时保存在一个内存缓冲区里面,等到缓冲区写满或者超过指定的时限之后,才真正地将缓冲区中的数据写入到磁盘中。
关于redis中数据存储的机制解析
这种方式CPU消耗低,但是数据安全性差,而且单次同步时间最长。如果用户不进行设置,默认值为everysec。相比于RDB持久化,AOF持久化执行的频率要高得多,所以AOF丢失数据的时间窗比RDB要小,但是也要耗费更多的CPU时间和IO资源。RDB和AOF还有一个不同点就是,RDB文件替换是一个原子操作所以RDB文件肯定是完整,而AOF文件有可能是不完整的,有可能命令没写完就宕机了或者磁盘坏了。但是也不用担心这种情况,一是这种情况出现的概率非常低,二是Redis提供了修复AOF文件的工具。
当Redis服务器长时间运行时,AOF文件的内容会越来越多,文件的体积也会越来越大,为了解决这个问题,Redis提供了AOF文件重写功能,消除一些冗余命令。
Redis提供了 BGREWRITEAOF命令来执行AOF重写,AOF重写不对旧AOF文件有依赖,而是通过查询现有数据库中的键值对的状态来生成一个新的AOF文件,重写动作在子进程中完成,生成一个新文件然后重命名替换掉老文件。在重写的过程中,客户端请求的新命令会追加到AOF重写缓冲区中,子进程完成重写之后,发送一个信号消息通知主进程把重写缓冲区中的内容同步到重写后的AOF文件中,这个过程会阻塞主进程。
通过设置appendfsync参数来设置AOF文件生成策略,它有三个可选值:
always,将AOF缓冲区的所有内容写入并同步到AOF文件中,这种方式数据安全性最高,但是CPU消耗大。everysec,将AOF缓冲区中的所有内容写入到AOF文件,如果上次同步AOF文件的时候距离现在超过一秒钟,那么再次对AOF文件进行同步,并且这个同步操作由一个线程专门负责执行,数据安全性不如always,当服务器出现故障时会出现1s的数据空窗期,但是CPU消耗较always小。no,将AOF缓冲区中的所有内容写入到AOF文件,但并不对AOF文件进行同步,何时同步由操作系统来决定。
关于Redis
redis是一个开源的使用C语言编写的一个kv存储系统,是一个速度非常快的非关系远程内存数据库。它支持包括String、List、Set、Zset、hash五种数据结构。除此之外,通过复制、持久化和客户端分片等特性,用户可以很方便地将redis扩展成一个能够包含数百GB数据和每秒处理上百万次的请求的系统。目前支持多种语言的api,方便用户使用。
redis同时也内置了事务、LUA脚本、复制等功能,提供两种持久化选项,一种是每隔一段时间将数据导入到磁盘(快照模式),另一种是追加命令到日志中(AOF模式)。如果只是作为高效的内存数据库使用也可以关闭持久化功能。通过哨兵(sentinel)和自动分区(Cuuster)的方式可以提高redis服务器的高可用性。
与关系型数据库相比,redis的命令请求不需要经过查询分析器或查询优化器进行处理,也避免了更新数据时引起的随机读\写,这些慢操作。它直接读写内存中的数据,并且数据是按照一定的数据结构存储的。所以它的速度非常快。
不同于memcached等完全基于内存的缓存中间件,Redis同时还提供了持久化功能,这也是为什么Redis不仅可以用来做数据缓存还可以用来做数据存储,服务器节点宕机之后可以通过事先持久化的数据还原数据到某个时间点的状态。Redis提供了两种持久化机制RDB和AOF,准确的讲应该是三种,Redis还提供了虚拟内存机制,但是性能比较差,使用场景有限。
RDB持久化是把当前数据库中的数据备份到一个RDB文件中,RDB文件是一个经过压缩的二进制文件,通过这个文件可以还原生成RDB文件时的数据库状态。
Redis提供了两个命令用于生成RDB文件,即SAVE和BGSAVE。SAVE命令会阻塞主进程,在执行该命令的过程中服务器会拒绝客户端命令。只有当SAVE命令执行完之后服务器才会继续处理客户端的命令,而BGSAVE命令是在子进程中执行,在执行该命令的过程中服务器还可以继续处理客户端的命令。SAVE命令和BGSAVE命令不能同时执行,当正在执行BGSAVE命令时,客户端发送的SAVE命令会被拒绝,两个BGSAVE命令也不能同时执行。
服务器在900秒之内对数据库进行了至少一次修改。服务器在300秒之内对数据库进行了至少10次修改。服务器在60秒之内对数据库进行了至少10000次修改。Redis通过一个saveparam结构体来保存save参数:
intset优化set
当set集合中的元素为整数且元素个数小于配置set-max-intset-entries值时,使用intset数据结构存储,否则转化为Dict结构,Dict实际是Hash Table的一种实现,key为元素值,value为NULL,这样即可在O(1)时间内判断集合中是否包含某个元素。
intset中有三种类型数组:int16_t类型、int32_t 类型、 int64_t 类型。至于怎么选择是那种类型的数组,是根据其保存的值的取值范围来决定的,初始化时是 int16_t,根据 set 中的***值在[INT16_MIN, INT16_MAX] , [INT32_MIN, INT32_MAX], [INT64_MIN, INT64_MAX]的那个取值范围来动态确定整个数组的类型。例如set一开始是 int16_t 类型,当一个取值范围在 [INT32_MIN, INT32_MAX]的值加入到 set 时,则将保存 set 的数组升级成 int32_t 的数组。
服务器结构体redisServer添加了三个字段:saveparams字段,保存所有的save参数。dirty字段,来保存上一次成功执行SAVE或BGSAVE命令之后,服务器对数据库执行的修改次数。lastsave字段,记录服务器上一次执行SAVE和BGSAVE的UNIX时间戳。RDB是通过备份某个时间点的数据来保存数据库状态,而AOF是通过保存服务器所执行的命令来保存数据库的状态的。当结点宕机重启时通过载入AOF文件并且执行文件中的命令就可以恢复生成AOF文件时的数据库状态,如果同时存在RDB文件和AOF文件,服务器优先载入AOF文件来还原数据库状态。
AOF实现分为三步:命令追加、文件写入、文件同步。现代操作系统中为了提高文件写入效率,当用户调用了write函数时操作系统通常会将写入的数据暂时保存在一个内存缓冲区里面,等到缓冲区写满或者超过指定的时限之后,才真正地将缓冲区中的数据写入到磁盘中。
关于redis中数据存储的机制解析
这种方式CPU消耗低,但是数据安全性差,而且单次同步时间最长。如果用户不进行设置,默认值为everysec。相比于RDB持久化,AOF持久化执行的频率要高得多,所以AOF丢失数据的时间窗比RDB要小,但是也要耗费更多的CPU时间和IO资源。RDB和AOF还有一个不同点就是,RDB文件替换是一个原子操作所以RDB文件肯定是完整,而AOF文件有可能是不完整的,有可能命令没写完就宕机了或者磁盘坏了。但是也不用担心这种情况,一是这种情况出现的概率非常低,二是Redis提供了修复AOF文件的工具。
当Redis服务器长时间运行时,AOF文件的内容会越来越多,文件的体积也会越来越大,为了解决这个问题,Redis提供了AOF文件重写功能,消除一些冗余命令。
Redis提供了 BGREWRITEAOF命令来执行AOF重写,AOF重写不对旧AOF文件有依赖,而是通过查询现有数据库中的键值对的状态来生成一个新的AOF文件,重写动作在子进程中完成,生成一个新文件然后重命名替换掉老文件。在重写的过程中,客户端请求的新命令会追加到AOF重写缓冲区中,子进程完成重写之后,发送一个信号消息通知主进程把重写缓冲区中的内容同步到重写后的AOF文件中,这个过程会阻塞主进程。
通过设置appendfsync参数来设置AOF文件生成策略,它有三个可选值:
always,将AOF缓冲区的所有内容写入并同步到AOF文件中,这种方式数据安全性最高,但是CPU消耗大。everysec,将AOF缓冲区中的所有内容写入到AOF文件,如果上次同步AOF文件的时候距离现在超过一秒钟,那么再次对AOF文件进行同步,并且这个同步操作由一个线程专门负责执行,数据安全性不如always,当服务器出现故障时会出现1s的数据空窗期,但是CPU消耗较always小。no,将AOF缓冲区中的所有内容写入到AOF文件,但并不对AOF文件进行同步,何时同步由操作系统来决定。
 相关技术资料
相关技术资料- 7-5CV/CC InnoSwitch3-AQ 开关电源 IC
- 7-5URF1DxxM-60WR3系列应用前景分析
- 7-51-6W URA24xxN-xxWR3G系列优势特征
- 7-5闭环磁通门信号调节芯片NSDRV401
- 7-5SK-RiSC-SOM-H27X-V1.1应用探究
- 7-5RISC技术8位微控制器参数设计
- 7-4超低功耗角度位置传感器参数技术封装
- 7-4四路输出 DC/DC 降压电源模块产品系列
- 7-4降压变换器和升降压变换器优特点及区别
- 7-4业界首创可在线编程电源模块 mEZ系列
- 7-4可编程门阵列 (FPGA)智能 电源解决方案
- 7-4高效先进封装工艺MPS 电源模块优势设计

 公网安备44030402000607
公网安备44030402000607





